
SOA(サービス指向アーキテクチャ)の概要
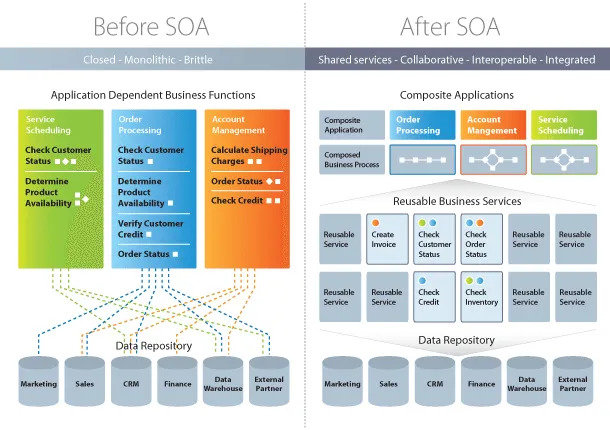
SOA(Service-Oriented Architecture、サービス指向アーキテクチャ)は、企業や組織が情報システムを構築・運用する際のアーキテクチャスタイルの一つです。システムの機能を「サービス」と呼ばれる独立した単位に分割し、それらを組み合わせることで全体の機能を実現します。各サービスは特定のビジネス機能やプロセスを担当し、他のサービスから独立して開発、デプロイ、管理が可能です。
サービスは再利用性が高く設計されており、異なるアプリケーションやプロセスからも利用できます。例えば、顧客情報を取得するサービスは、販売システムやカスタマーサポートシステムなど、複数の業務領域で共通して利用できます。このように、サービスの再利用性を高めることで、開発効率の向上や保守コストの削減が期待できます。
各サービスは明確に定義されたインターフェースを通じて通信します。インターフェースは一般的に標準化されたプロトコル(SOAP、RESTなど)やデータ形式(XML、JSONなど)を使用しており、異なるプラットフォームや言語で実装されたサービス間でも相互運用性が確保されます。これにより、既存のシステムやコンポーネントを統合しやすくなり、システム全体の柔軟性が向上します。また、サービス指向の設計により、システムの変更や拡張が容易になります。新しいビジネス要件が発生した場合でも、必要なサービスを追加または既存のサービスを組み合わせることで対応できます。全体のシステムに大きな影響を与えることなく、部分的な変更が可能となるため、ビジネス環境の変化に迅速に適応できます。
構成する要素の詳細

サービス
サービスは、SOAの基本的な構成要素であり、特定の機能やビジネスロジックを提供する独立したコンポーネントです。それぞれのサービスは、特定の業務プロセスや機能を実装しており、他のサービスやアプリケーションから呼び出して利用できます。この独立性により、サービスは再利用可能で、他のシステムやプロジェクトでも容易に統合できます。また、サービスは疎結合で設計されているため、個々のサービスの変更や更新が他のサービスに及ぼす影響を最小限に抑えることができます。
サービスは多様な技術スタックやプラットフォームで実装することが可能です。これは、SOAが標準化されたインターフェースやプロトコルを使用してサービス間の通信を行うためです。そのため、異なるプログラミング言語やデータベース、ハードウェア環境で開発されたサービスでも、相互に連携して機能を提供できます。この柔軟性は、既存システムの資産を活用しつつ、新しい技術を導入する際にも有用です。
サービスインターフェース
サービスインターフェースは、サービスが外部に対して提供する機能やデータを定義するためのものです。インターフェースは、サービスの利用者がどのようにサービスを呼び出し、どのようなデータをやり取りするかを明確にします。これには、メソッドのシグネチャやパラメータの形式、戻り値の型などが含まれます。サービスインターフェースは、標準化されたプロトコル(例えば、SOAPやREST)やデータフォーマット(XMLやJSON)を使用して定義されることが一般的です。
サービスインターフェースを明確に定義することで、サービスの実装と利用者の間に契約が成立し、サービスの内部実装に依存しない形で利用が可能となります。この契約により、サービスの内部実装を変更しても、インターフェースが変わらない限り、利用者側への影響を避けることができます。また、インターフェースの標準化により、異なる言語やプラットフォームで実装されたサービス間でも相互運用性が確保されます。
サービスプロバイダー
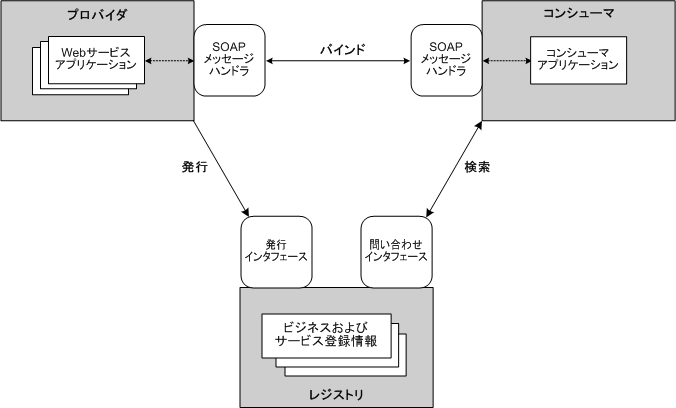
サービスプロバイダーは、SOAにおいてサービスを開発・提供する主体です。特定のビジネス機能やデータを外部に提供するために、サービスを実装し、そのインターフェースや契約を公開します。サービスプロバイダーは、自身のサービスをサービスレジストリに登録することで、他のシステムやアプリケーション(サービスコンシューマー)がそのサービスを発見し、利用できるようにします。
サービスコンシューマー
サービスコンシューマーは、SOAにおいて他のサービスが提供する機能を利用する主体です。自らが必要とするビジネス機能を実現するために、サービスプロバイダーが提供するサービスを呼び出します。サービスコンシューマーは、サービスレジストリを参照して必要なサービスを発見し、公開されたインターフェースを通じてサービスにアクセスします。
サービスレジストリ
サービスレジストリは、利用可能なサービスのメタデータを格納するリポジトリです。サービスの名称、位置、インターフェースの詳細、バージョン情報などを管理し、サービスの検索やバインディングをサポートします。サービスレジストリにより、サービスの利用者は必要なサービスを容易に見つけ、動的にバインドすることができます。
サービスレジストリは、サービスの可視性と管理性を向上させます。開発者やシステム管理者は、レジストリを参照することで、どのようなサービスが存在し、どのように利用できるかを把握できます。また、サービスのバージョン管理やライフサイクル管理にも役立ちます。新しいサービスの追加や既存サービスの更新時に、レジストリを更新することで、システム全体の整合性を保ちます。
ESB(Enterprise Service Bus)
ESBは、サービス間の通信や統合を支援するためのミドルウェアです。メッセージのルーティング、プロトコル変換、メッセージの変換(データフォーマットの変換)、セキュリティ、トランザクション管理など、多岐にわたる機能を提供します。ESBを使用することで、複雑なシステム間の連携を容易に行うことができます。例えば、企業内に複数のシステムが存在し、それぞれが異なる技術やプロトコルで実装されている場合を考えます。販売管理システムはSOAPを使用し、在庫管理システムはRESTを使用、会計システムは独自のプロトコルを使用しているとします。このような場合、直接システム同士を連携させるのは困難です。ESBを導入することで、各システムはESBと通信するだけで済み、ESBがプロトコル変換やデータ変換を行ってくれます。また、ESBはメッセージのルーティング機能を持っており、特定の条件に基づいてメッセージを適切なサービスに転送することができます。例えば、注文処理のメッセージを、注文金額に応じて通常の処理システムと特別な承認プロセスを持つシステムに振り分けることが可能です。さらに、ESBはメッセージの同期・非同期通信をサポートしており、システム間の疎結合を実現します。
セキュリティ面でも、ESBは重要な役割を果たします。認証・認可の管理や、メッセージの暗号化・復号化、セキュリティポリシーの適用などを集中管理できます。これにより、各サービスで個別にセキュリティ対策を実装する必要がなくなり、全体のセキュリティレベルを向上させることができます。
具体例として、Apache CamelやMule ESB、IBM Integration Busなどの商用・オープンソースのESBソリューションが存在します。これらは、多機能で拡張性が高く、大規模なエンタープライズ環境でのシステム統合に適しています。企業は、ESBを活用して既存システムの統合や新規サービスの追加を効率的に行い、ビジネスプロセスの最適化や市場への迅速な対応を実現しています。
SOAP(Simple Object Access Protocol):
SOAPは、XMLベースのメッセージプロトコルであり、ウェブサービス間の通信に広く使用されています。SOAPは、メッセージのフォーマットや通信の手順が厳格に定義されているため、信頼性の高い通信が求められるエンタープライズ環境でよく採用されます。例えば、金融機関間での取引データのやり取りや、企業間での受発注情報の交換など、高度なセキュリティとトランザクション管理が必要な場面で活用されています。SOAPは、WS-SecurityやWS-Addressingといった拡張仕様をサポートしており、メッセージの暗号化やデジタル署名、メッセージのルーティング情報の付加などが可能です。これにより、複雑なビジネス要件やセキュリティ要件に対応したシステムを構築できます。また、SOAPはHTTPだけでなく、SMTPやJMSなど他の通信プロトコルとも組み合わせて使用できる柔軟性を持っています。
REST(Representational State Transfer):
RESTは、HTTPを利用した軽量な通信プロトコルであり、ウェブサービスの設計アーキテクチャとして広く普及しています。RESTは、リソース指向のアーキテクチャに適しており、URLでリソースを指定し、HTTPメソッド(GET、POST、PUT、DELETEなど)を用いて操作を行います。例えば、SNSのAPIや天気情報、地図情報などを提供するウェブサービスでRESTが採用されています。RESTは、シンプルで直感的な設計が可能であり、開発者が理解しやすいという利点があります。さらに、ステートレスな通信を前提としているため、サーバ側の負荷を軽減できます。モバイルアプリケーションやシングルページアプリケーション(SPA)との連携においても、RESTは高い適合性を示しています。また、JSON形式のデータを使用することで、データの軽量化と高速な処理が可能になります。
SOAのメリットとデメリット
メリット
再利用性の向上:
サービスをモジュール化することで、個々のサービスが独立して機能を提供できるようになります。一度開発したサービスを他のプロジェクトやシステムでも容易に利用することが可能となります。例えば、顧客情報を取得するサービスを開発した場合、販売管理システムやカスタマーサポートシステムなど、複数の業務システムで同じサービスを共有できます。サービスの再利用性が高まることで、開発コストの削減や開発期間の短縮が期待できます。
柔軟性と拡張性:
SOAでは、新しいサービスの追加や既存サービスの変更が容易に行えます。サービス間は疎結合であるため、特定のサービスを更新してもシステム全体への影響を最小限に抑えることができます。例えば、新たなビジネス要件が発生した際に、その要件に対応するサービスを追加するだけで対応可能です。システム全体を再構築する必要がないため、柔軟な拡張が可能となります。
異種システム間の統合:
異なる技術やプラットフォームで実装されたサービスでも、標準化されたインターフェースを通じて統合が可能です。既存のシステム資産を活用しながら、新しいシステムやサービスを導入できます。例えば、古いメインフレーム上のシステムと最新のクラウドベースのサービスを統合し、一貫した業務プロセスを実現することができます。異種システム間の連携が容易になることで、全体の業務効率が向上します。
開発効率の向上:
サービスを分割することで、複数の開発チームが同時に異なるサービスの開発を進めることができます。その結果、プロジェクト全体の開発期間を短縮できます。また、各サービスが明確な責任範囲を持つため、開発やテストの効率も向上します。開発プロセスが効率化されることで、より迅速なシステムのリリースが可能となります。
ビジネスニーズへの迅速な対応:
ビジネス環境の変化に対して、システムを柔軟に適応させることができます。新しいビジネスプロセスや機能を必要とする場合でも、必要なサービスを追加または組み合わせることで迅速に対応できます。市場の変化や顧客の要求に対してタイムリーに応答でき、競争力を維持することが可能です。
デメリット
複雑性の増加:
サービス間の連携や管理が複雑になり、システム全体の設計や運用に高度な知識が必要となります。サービスが増えるにつれて、依存関係や通信経路が複雑化し、全体の把握が困難になる可能性があります。また、サービスの統合や変更を行う際には、適切な設計パターンやベストプラクティスを理解していないと、システムの品質が低下するリスクがあります。
性能への影響:
サービス間の通信が増加するため、ネットワーク遅延や通信オーバーヘッドが発生し、システム性能に影響を与える可能性があります。特に、サービスが細分化されすぎると、処理を完了するために多数のサービス呼び出しが必要となり、レスポンス時間が長くなることがあります。性能を最適化するためには、通信の最適化やキャッシュの利用などの対策が必要です。
セキュリティリスク:
サービスがネットワークを通じて通信するため、セキュリティ対策が不十分だと不正アクセスやデータ漏洩のリスクが高まります。各サービス間の通信経路を保護する必要があり、認証・認可、データの暗号化、セキュリティポリシーの適用など、包括的なセキュリティ対策が求められます。セキュリティを確保するための設計と運用が複雑化する可能性があります。
コストの増大:
ESBなどのミドルウェアの導入や運用にかかるコストが増える場合があります。ミドルウェア自体のライセンス費用やハードウェアコスト、導入に必要な人件費などが発生します。また、運用・保守のための専門知識を持った人材が必要となり、人件費や教育コストも増加します。これらのコストが総合的に影響し、プロジェクトの投資利益率(ROI)に影響を与える可能性があります。
SOAとマイクロサービスアーキテクチャの違い
サービスの粒度:
SOA(サービス指向アーキテクチャ)では、サービスは比較的大きな機能単位で設計されます。これは、企業のビジネスプロセス全体をサポートするような、広範な機能を持つサービスを構築することが多いためです。これにより、サービスは複数の機能や業務ロジックを内包し、再利用性を高めることを目指します。一方、マイクロサービスアーキテクチャでは、サービスをより小さな機能単位に細分化します。各マイクロサービスは特定のビジネス機能やドメインに焦点を当て、単一の目的を持つ小さなコンポーネントとして設計されます。この違いにより、マイクロサービスは変更やデプロイが容易で、チームが独立して開発を進めることができます。
通信方式:
SOAでは、サービス間の通信にESB(エンタープライズサービスバス)を用いることが一般的です。ESBは、メッセージのルーティングやプロトコル変換、トランザクション管理などの高度な機能を提供し、複雑なビジネスロジックを統合します。しかし、その結果として通信が重厚で複雑になり、設定や管理が難しくなる傾向があります。一方、マイクロサービスアーキテクチャでは、軽量なHTTPプロトコルやメッセージングキューを使用してサービス間の通信を行います。例えば、RESTful APIやgRPC、メッセージブローカーとしてRabbitMQやKafkaを利用し、シンプルで効率的な通信を実現します。このアプローチにより、サービス間の結合度を下げ、システムの柔軟性と拡張性を高めることができます。
デプロイ:
SOAでは、複数のサービスが同一のアプリケーションサーバ上で動作することが多く、サービスのデプロイや管理が集中化されています。これにより、一貫した環境での運用が可能となりますが、サービスの一部に変更があった場合でも、全体の再デプロイが必要になることがあります。一方、マイクロサービスアーキテクチャでは、各サービスが独立してデプロイされます。各マイクロサービスは独自のプロセスやコンテナで実行され、サービスごとにスケーリングやアップデートが可能です。この独立性により、特定のサービスに変更を加える際に他のサービスへの影響を最小限に抑えることができ、継続的デプロイやDevOpsの実践が容易になります。
技術スタック:
SOAでは、統一された技術スタックを使用する傾向があります。つまり、全てのサービスが同じプログラミング言語、フレームワーク、データベースを共有します。これにより、開発や保守の効率化が図られ、組織全体での技術的な一貫性が保たれます。しかし、特定のサービスに最適な技術を採用する柔軟性が制限される場合があります。一方、マイクロサービスアーキテクチャでは、各サービスごとに最適な技術を選択できます。開発チームは、サービスの要件に応じて最適なプログラミング言語やデータストレージ、フレームワークを選ぶことができます。この多様性により、各サービスがその機能を最も効率的に実現できますが、全体としての技術的な複雑性が増し、異なる技術スタック間での知識共有や運用管理が難しくなる可能性があります。
サービス指向アーキテクチャの設計例
複合システムデザインにおけるマイクロサービスアーキテクチャの説明に則り、こちらでもサービス指向アーキテクチャによるWordPress設計例を紹介します。とはいえ、これから紹介するアーキテクチャは、クラウドサービスを組み合わせてWordPressを実現した例で、厳密にSOAの例ではありません。サービスコンピューティングの授業ではこれからクラウドサービスを組み合わせた実習を行なっていきますので、その意味では良い具体例といえます。

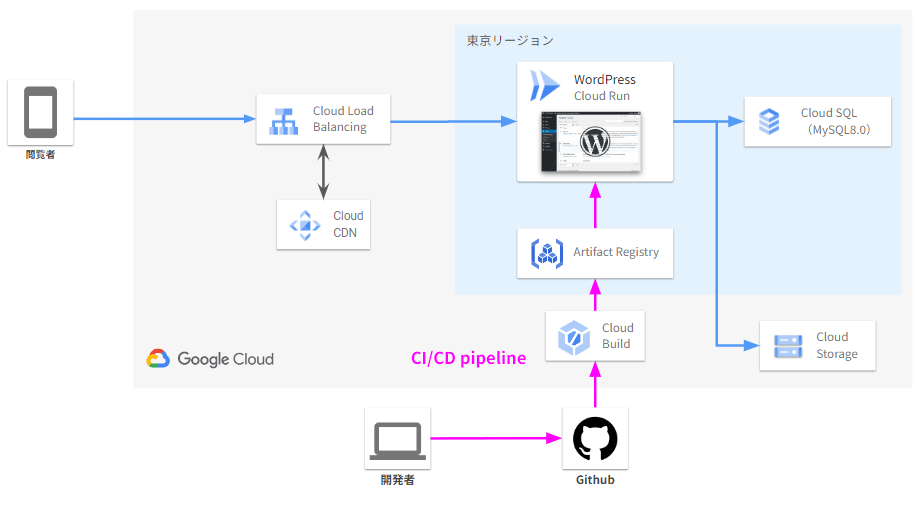
比較のためにAWSによるWordPress構築のベストプラクティスの図も示します。
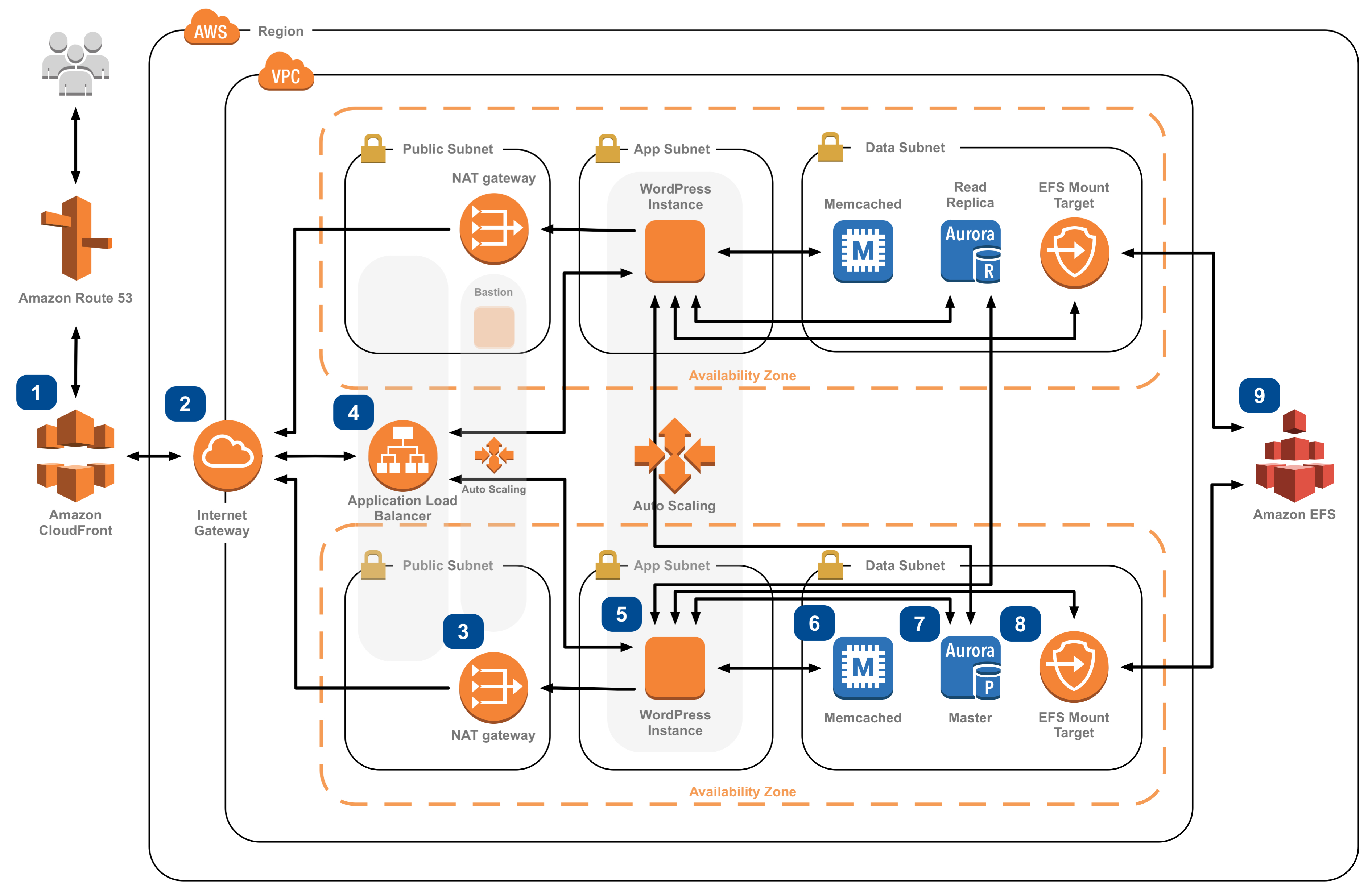
上記では、ロードバランサーとしてCloud Load Balancingが、WordPressインスタンスの代わりに、CloudRun上に展開されたWordPressが、Aurora(AWSのデータベース)の代わりにCloudSQLが、マウントされたストレージシステム(EFS)の代わりにCloud Storageがそれぞれ採用されていることがわかります。それぞれを既存のサービスの組み合わせで構築することで、AWSの構築例と比較して、シンプルにシステム構築ができていることがわかると思います。それぞれのサービスは、サーバレス(仮想マシンやコンテナの立ち上げを要しない)で構築でき、真にオンデマンドなサービス構成といえます。
また、CI(Continuous Integration, 継続的インテグレーション)と、CD(Continuous Development, 継続的デプロイメント)のための機構も備えています。
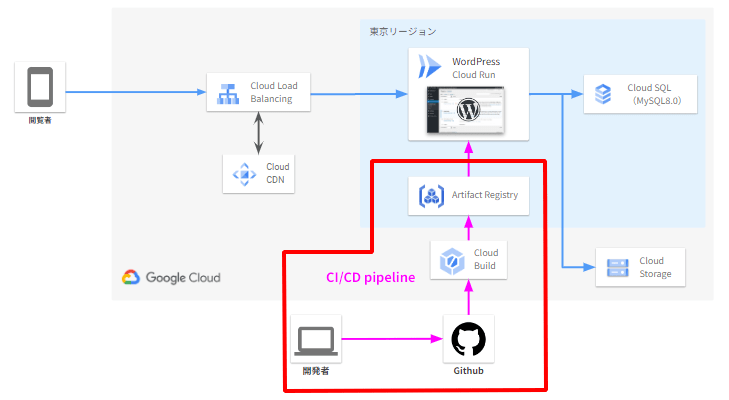
これからの演習でも、このパイプラインのような構築方法を実践していきます。
注意: AWSにも同じような機能を持つサーバレスのサービスは存在します。上記の比較は設計が似ているために対比させていますが、Google CloudとAWSの差と言うわけではありません。
Webアプリケーションフレームワーク
今回の演習は、これからの演習を構成する上で最も基礎となるWebアプリケーションフレームワークであるFlaskについて学んでいきます。Flaskは、Pythonで作られた軽量なウェブアプリケーションフレームワークです。シンプルで学習しやすく、初心者からプロの開発者まで幅広く利用されています。必要な機能だけを選んで追加できるため、柔軟な開発が可能です。小規模なプロジェクトやプロトタイプの作成に適しており、迅速な開発をサポートします。テンプレートエンジンとしてJinja2を使用し、URLルーティングやデバッグツールなどの基本機能を備えています。また、さまざまな拡張機能を使って機能を拡張することもできます。実世界コンピューティングプロジェクトIIの第二回の演習の中で、Dockerアプリケーションとして組み込まれていたことを覚えている人も多いと思います(先週だし・・)。実世界コンピューティングプロジェクトIIでは、フレームワークの解説はほとんどやりませんでしたが、ここでは、より詳細に解説していきます。Flaskの機能は以下のとおりです。
シンプルで柔軟な設計
Flaskは最小限の機能のみを提供するマイクロフレームワークとして設計されています。必要な機能はPythonのモジュールやパッケージとして追加できます。たとえば、import文を使って必要なライブラリをインポートし、機能を拡張します。
from flask import Flask
app = Flask(__name__)
内蔵の開発用サーバーとデバッガ
FlaskはwerkzeugというWSGIユーティリティを使用しており、開発用サーバーは簡単に起動できます。デバッガもPythonの例外処理を活用し、エラー発生時に詳細なスタックトレースを提供します。
if __name__ == '__main__':
app.run(debug=True)
Jinja2テンプレートエンジンの採用
JinjaはFlaskと組み合わせて使われるテンプレートエンジンで、PythonのデータをHTMLに埋め込むことができます。render_template関数を使用してテンプレートをレンダリングします。
from flask import render_template
@app.route('/')
def index():
return render_template('index.html', message='Hello, World!')
URLルーティングの簡潔さ
URLルーティングとは、ウェブアプリケーションにおいて、特定のURLパス(例: /home や /about)に対して適切な処理や機能を結びつける仕組みのことです。ユーザーがブラウザで特定のURLをリクエストした際、そのリクエストをどの関数やメソッドで処理するかを決定する役割を果たします。
簡単な例を挙げると:
- ユーザーが
/loginにアクセスすると、ログインページを表示する関数が呼び出されます。 - ユーザーが
/profileにアクセスすると、ユーザーのプロフィール情報を表示する関数が実行されます。
このように、URLルーティングを使うことで、ウェブアプリケーションはさまざまなURLに応じて適切なレスポンスを返すことができます。開発者はURLパスと処理内容を関連付けることで、アプリケーションの機能を構築していきます。
例えば、Flaskでの実装例:
from flask import Flask
app = Flask(__name__)
@app.route('/hello')
def hello():
return 'こんにちは、世界!'
@app.route('/user/<username>')
def show_user_profile(username):
return f'ユーザー名: {username}'
if __name__ == '__main__':
app.run(debug=True)このコードでは、
/helloにアクセスすると、"こんにちは、世界!" というメッセージが表示されます。/user/任意のユーザー名にアクセスすると、そのユーザー名を含むページが表示されます。
URLルーティングは、ウェブアプリケーションのナビゲーションと機能性を実現する基本的な要素であり、ユーザーのリクエストを適切に処理するために不可欠な仕組みです。
拡張性の高さ
Flaskは拡張機能を通じて機能を追加できます。これらはPythonのパッケージとして提供され、pipでインストールしてimport文で利用します。代表的な例として、FlaskとSQLAlchemyを統合するFlask-SQLAlchemy拡張があります。これにより、データベース操作をオブジェクト指向的に行うことが可能になります。Flaskが高性能なWebフレームワーク(PythonだとDjango)などと比較して軽量と言われているのは、このようなORMapperの機能をデフォルトでは持っていないことがその理由として挙げられます。
from flask_sqlalchemy import SQLAlchemy
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///example.db'
db = SQLAlchemy(app)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True, nullable=False)
def __repr__(self):
return f'<User {self.username}>'
# データベースの作成
db.create_all()
上記のように、Flask-SQLAlchemyを使ってモデルクラスを定義し、データベースとのマッピングを行うことができます。
ORMapper
ORMapper(Object-Relational Mapper)とは、オブジェクト指向プログラミング言語のオブジェクトとリレーショナルデータベースのテーブルとの間でデータを相互変換するための技術です。開発者はデータベースの複雑なSQLクエリを直接書く必要がなく、プログラム内のオブジェクトやクラスを通じてデータ操作を行えます。これにより、コードの可読性や保守性が向上し、データベース操作がより直感的になります。代表的なORMapperのツールには、PythonのSQLAlchemyやDjango ORM、JavaのHibernateなどがあります。
SQLAlchemy
SQLAlchemyは、Pythonで利用される強力なデータベースツールキットおよびORマッパー(ORM)です。リレーショナルデータベースとオブジェクト指向プログラミングを橋渡しし、データベース操作を直感的かつ効率的に行うことができます。以下に、具体的なコード例を示しながら解説します。
【課題】Flaskを用いたWebアプリの試作
では具体的にFlaskでアプリケーションを作っていきましょう。Webアプリの実装で最も簡単な例の一つはフォームの実装です。ここからは、GET, POSTメソッドの実装を通じて、Flaskでフォームを作ってみましょう。来週以降、作ってもらったFlaskアプリをクラウドサービスを使って、Webに公開していってもらいます。
0. 環境づくり
本授業では、コード編集としてVisual Studio Code(VSCode)を使います。まだインストールできていない方は、brewを使ってインストールしましょう。すでに入っている人は、再インストールする必要はありません。他のエディタでも良い・・と思われる方もいるかもしれませんが、今後、Google Cloudを使った演習をしていくとき、VSCodeのプラグインを使います。その時になって困ると思いますので、指示に従ってください(Google Cloudも自分で対応できるという方は好きにしてください。ただし、質問されてもVSCode以外の環境については基本対応しません。)
brew install --cask visual-studio-code次に、授業の作業用ディレクトリを作ってください。これからのことを考えて、 service_computing/lecXX と言った名前で作ると良いでしょう(XXは授業回の番号)。
mkdir -p service_computing/lec02
cd service_computing/lec02
touch app.py授業によって、さまざまなPython環境が設定されている気がしますので、まず以下のコマンドが動くかを確認してください。または、上記のコマンドを動かす設定ができる人は設定しましょう(pyenvなど)。
❯❯❯ python3
Python 3.12.6 (main, Sep 6 2024, 19:03:47) [Clang 15.0.0 (clang-1500.3.9.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> ^D
❯❯❯ pip3
Usage:
pip3 <command> [options]
...Pythonがすでにインストールされている場合
pip3を使ってflaskをインストールしましょう。
pip3 install flaskPythonまたはPiP3がインストールされていない場合
pipenvを使った環境構築をしましょう。service_computing/ で作業してください。
cd ..
brew install python3
brew postinstall python3
brew install pipenv
pipenv install flask
pipenv shell
(service_computing) ❯❯❯ cd lec02
(service_computing) lec02 ❯❯❯ pipenv shell コマンドを使うことで授業用の環境が作られますので、これからこれでアプリのテストをしていくと良いと思います。
1. 必要なモジュールのインポートとアプリケーションの作成
ここからは、app.pyを編集していきましょう。まず、Webアプリケーションを実行する主体となるappインスタンスが作成します。
from flask import Flask, request, render_template
app = Flask(__name__)2. GETリクエストの処理
2.1 シンプルなGETリクエスト
次に試しにシンプルなGETリクエストを作成してみましょう。
@app.route('/', methods=['GET'])
def index():
return 'これはGETリクエストのレスポンスです。'上記の関数を実装することでユーザーが/にアクセスすると、指定したメッセージが表示されます。
デコレータのmethods=['GET']はこのルートがGETリクエストのみを受け付けることを指定しています。
2.2 GETリクエストでパラメータを受け取る
GETリクエストでパラメータを受け取るためには、以下のようにgreet関数を設定すると良いです。
@app.route('/greet', methods=['GET'])
def greet():
name = request.args.get('name', 'ゲスト')
return f'こんにちは、{name}さん!'request.args.get('name') を使うことでURLのクエリパラメータnameの値を取得します。パラメータが指定されていない場合は'ゲスト'を使用することも指定されています。アドレス/greet?name=太郎 にアクセスすると、こんにちは、太郎さん! と表示されます。
3. POSTリクエストの処理
3.1 シンプルなPOSTリクエスト
続いて、シンプルなPOSTリクエストを実装してみましょう
@app.route('/submit', methods=['POST'])
def submit():
data = request.form.get('data')
return f'受け取ったデータ: {data}'request.form.get('data') 関数でフォームデータのdataフィールドの値を取得します。
3.2 HTMLフォームからのPOSTリクエスト
POSTはやはり、HTMLフォームから実行されることが多いので、その作り方を見ていきましょう。
lec02 ディレクトリの下に、templatesというディレクトリを作り、その下にform.htmlファイルを以下のように作りましょう。
templates/form.html:
<!DOCTYPE html>
<html>
<head>
<title>POSTリクエストの例</title>
</head>
<body>
<h1>データ送信フォーム</h1>
<form action="/submit" method="post">
<label for="data">データを入力してください:</label>
<input type="text" id="data" name="data">
<input type="submit" value="送信">
</form>
</body>
</html>その上で、以下の関数を実装することで、
@app.route('/form', methods=['GET'])
def form():
return render_template('form.html') /form にアクセスすると、データを入力して送信できるフォームが表示されます。templates/form.htmlにあるようにPOSTが行われうrと /submit エンドポイントにデータがPOSTリクエストとして送信されます。
4. GETとPOSTの両方を処理するルート
多くのフォームは、GETとPOST両方のリクエストを受け付けます。その実行方法を見ていきましょう。templates/form.html と同様に、login.htmlをtemplatesディレクトリの下に作りましょう。
templates/login.html:
<!DOCTYPE html>
<html>
<head>
<title>ログイン</title>
</head>
<body>
<h1>ログインフォーム</h1>
<form action="/login" method="post">
<label for="username">ユーザー名:</label>
<input type="text" id="username" name="username"><br><br>
<label for="password">パスワード:</label>
<input type="password" id="password" name="password"><br><br>
<input type="submit" value="ログイン">
</form>
</body>
</html>その上で、GET/POST両方に対応する関数は次のような実装になります。
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
username = request.form.get('username')
password = request.form.get('password')
# ここで認証処理を行う
return f'ユーザー名: {username}, パスワード: {password}'
else:
return render_template('login.html')login関数では、
- GETリクエストの場合: ログインフォームを表示。
- POSTリクエストの場合: フォームデータを受け取り、処理を行います。
5. ファイルのアップロード
最後にファイルのアップロードを行う実装について紹介します。以下のupload関数は、指定されたファイルをアップロードし、uploadsディレクトリ下に保存します。保存先が必要なので、あらかじめ、 uploads フォルダは作成しておかなければいけません。
import os
from werkzeug.utils import secure_filename
UPLOAD_FOLDER = './uploads'
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
@app.route('/upload', methods=['GET', 'POST'])
def upload():
if request.method == 'POST':
if 'file' not in request.files:
return 'ファイルが選択されていません'
file = request.files['file']
if file.filename == '':
return 'ファイル名が空です'
if file:
filename = secure_filename(file.filename)
file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))
return 'ファイルがアップロードされました'
else:
return render_template('upload.html')templates/upload.html:
<!DOCTYPE html>
<html>
<head>
<title>ファイルアップロード</title>
</head>
<body>
<h1>ファイルをアップロード</h1>
<form action="/upload" method="post" enctype="multipart/form-data">
<input type="file" name="file">
<input type="submit" value="アップロード">
</form>
</body>
</html>8. アプリケーションの実行
最後にアプリケーションを実行しましょう。
if __name__ == '__main__':
app.run(debug=True)【課題提出】以下の操作をして、Classroomに作業フォルダのアーカイブをアップロードしてください。
以下のコマンドを実行し、Flaskでアプリケーションを立ち上げましょう。
python3 ./app.pyその上で、
にアクセスして、意図した動作であることを確認しましょう。/submitはブラウザから確認できません。ターミナルから以下を実行して確認してください。
❯❯❯ curl -X POST --data-urlencode 'data=hello world' http://127.0.0.1:8000/submit
受け取ったデータ: hello world⏎最後に、フォームの動作を確認しましょう(実は、/submitは/formでも確認できます)。
にそれぞれアクセスし、フォームの動作を確認してください。/uploadには、Classroomにあるkdix.pngをアップロードしてください。全ての動作確認が終わったら、lec02ディレクトリをzipファイルにまとめて、Classroomの課題提出フォームに提出してください(下記参照、lec02.zipができるはずです)。
この課題は、変更するところもなく、比較的簡単だと思いますが、ソースコード、ディレクトリなどをしっかりと配置しないと動作しません。解説を読みながら、読み落としがないように実行してください。
トラブルシューティング
python ./app.py を実行すると、ポート5000がすでに使用中の場合があります。その場合は、app.run 関数の引数にポート番号を与えることで、違うポートでサーバを起動できます。
if __name__ == '__main__':
app.run(debug=True, port=8000)上記の例では、デフォルトの5000番の代わりに8000番でサーバを立ち上げることができます